Three Mistakes to Avoid When Creating a Hidden Layer Neural Network

Machine learning is predicted to generate approximately $21 billion in revenue by 2024, which makes it a highly competitive business landscape for data scientists.
Coincidently, hidden layers neural networks – better known today as deep learning – are generating tons of excitement in the AI and machine learning industry as a result of developments in computer vision, speech recognition, and text processing.
Neural networks do have constraints because of limited bandwidth. However, these can be overcome in layered control systems with components having a diversity of speed-accuracy trade-offs, which enables data scientists to gain accurate control.
In this article, we’ll dive deep (pun intended) into:
- What Are Neural Networks?
- What Are Hidden layers and How They Work?
- Common Mistakes With Hidden Layers – And How To Fix Them
Let’s begin!
What Is a Hidden Layer Neural Network?
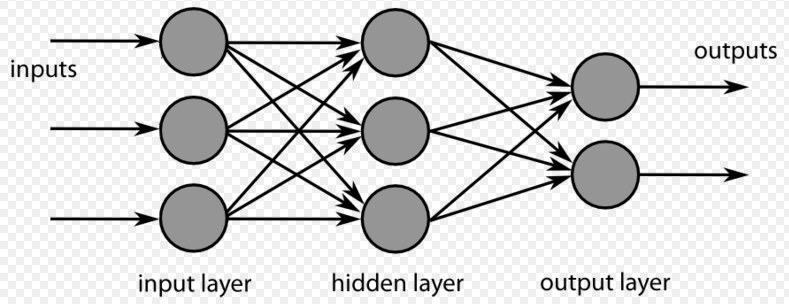
Like other machine learning models, neural networks are a series of algorithms that aim to recognize relationships between data and use this to make predictions and classify data.
You’re probably wondering why “neural” networks of all names. Well, these network algorithms mimic the processes that neurons in the cerebral cortex of the human brain use to distinguish data, hence the name!
Given that neural networks can adapt to constantly changing input, they can generate infinite results without having to redesign the output criteria. Think of it as a process that helps you cluster and classify data – helping you to recognize patterns and relationships among your data and group them according to similarities.
Let’s have a look at the different types of layers a neural network can have:
Input Layer
The input layer is responsible for passing on information from external sources (such as CSV files or a web service) to subsequent layers in the neural network.
While there is no limit to how many input layers you can have in a neural network, you need to have at least one for it to function.
Output Layer
So what is an output layer in a neural network?
The output layer processes the final computations on the input received and transfers the information from the neural network to the outside world – producing the final result.
Data scientists need to have at least one output layer in a neural network.
Hidden Layer
What is a hidden layer in a neural network? While their introduction isn’t compulsory, hidden layers are what set neural networks apart from most machine learning algorithms. They’re cozied up between the input and output layers, which is how they got their name.
What is the number of hidden layers in a neural network? Depending on your computing needs, you can have as little or as many hidden layers in a neural network as you want. You can even have a neural network without hidden layers.
While one hidden layer computing power to solve a majority of problems, a large number of hidden layers can solve more complex issues associated with greater weight. It performs nonlinear transformations of the input you enter into the network.
Typically, each hidden layer in a neural network contains the exact same number of neurons.
How Does a Hidden Layer Work?
Now that you know what hidden layers are, let’s dive into how they work.
Hidden layers are designed to perform unique mathematical functions to produce specialized output for the defined result you need. They break down the function of a neural network into specific transformations of the data.
For example, some neural network hidden layers have a squashing functions, which are particularly useful when you need an output that is a probability, as the network will then take input and produce an output value between 0 and 1 i.e. a probability.
So, what is the advantage of a hidden layer in a neural network?
- They provide the appropriate discrimination needed to cluster and classify data
- They offer more scope than single-layer Perceptrons, which can only solve linearly separable problems
- They can capture and reproduce extremely complex input-output relationships
Most Common Mistakes With Hidden Layer Neural Networks
A neural network should mimic any continuous function thrown it’s way. However, many times data scientists are stuck with low-performing networks and struggle to get decent results.
We’ve been there, which is why we’re here to help. If there’s one bit of advice the team at SuperDataScience has to give, it’s to say that you should approach the problem statistically – instead of simply trusting your gut.
With that in mind, here are three avoidable mistake data scientists should take note of when creating hidden layers:
Number of Neurons in a Hidden Layer
One of the most common issues data scientists face is to determine the number of neurons in a hidden layer.
This is a crucial step because neural network hidden layers are trained to get small errors. A bit of advice from our side – too many nodes are undesirable, but you need to have enough to be able to capture complex input-output relationships.
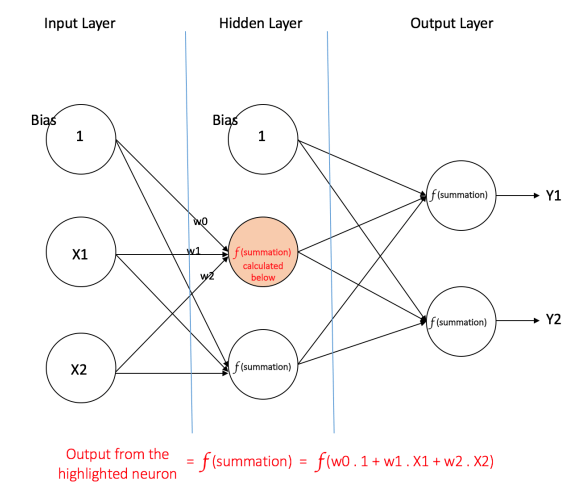
Ultimately though, obtaining optimal dimensionality is a trial and error process. While you can spend your days hitting (and missing!), you’ll need a reliable point from which to start. According to research by Dr. Jeff Heaton here are three tips to help guide you on selecting the dimensionality of a hidden layer:
- If you think the input-output relationship you desire is a straightforward one, start with a hidden-layer dimensionality that is two-thirds of that of your input layer.
- If you believe that the input-output relationship is complex, then:
Hidden-Layer Dimensionality = Input Dimensionality + Output Dimensionality
- Furthermore, if you think the input-output relationship needs more computing power than this, set the hidden dimensionality to less than twice the input dimensionality.
How Many Hidden Layers Should a Neural Network Have?
There’s no simple answer to this question.
A single hidden layer has immense computational power. So, if you find yourself needing more, check your neural network for other improvements before you make any architectural change. This make includes the network’s learning rate or your training data set.
More layers only add to the processing time and complexity of the code. This not only wastes your time and coding efforts, but it’s also a waste of your resources. As a result, the effects of hidden layers in a neural network makes it susceptible to overtraining.
This brings us to our next point.
Overtraining
Overtraining issues arise when the network matches data too close to each other, thus losing its generalization ability initially gained from the test data.
This is vaguely similar to how we tend to overthink a situation. By focusing excessively on minuscule details and breaking down a problem that is quite simple, neural networks can process output that misses the mark.
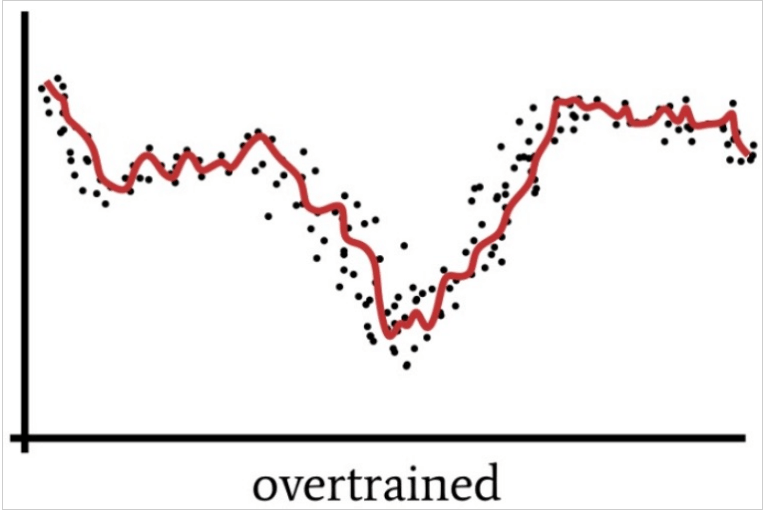
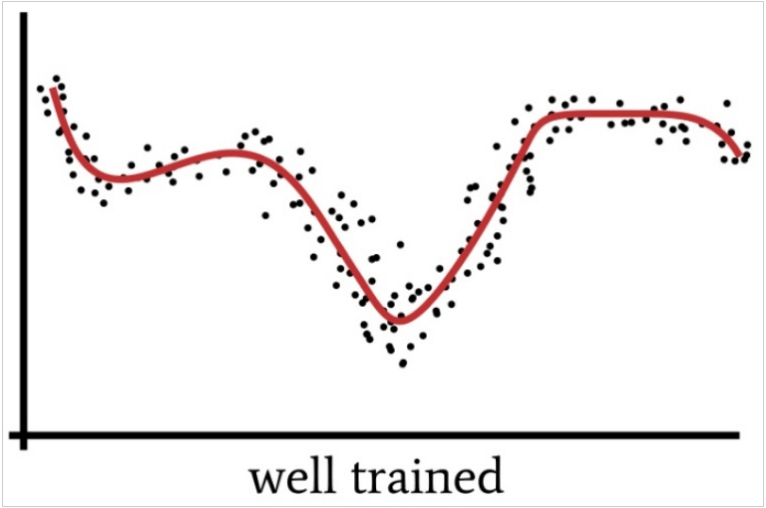
One hidden layer enables a neural network to approximate all functions that involve continuous mapping from one finite space to another. On the other hand, two hidden layers allow the network to represent an arbitrary decision boundary and accuracy.
The best advice we can impart is to say that data scientists can find their desired results in two or less hidden layers.
Key Takeaways
- There’s no right or wrong number of hidden layers in a neural network – their use and architecture depend on how much computing power you need.
- Layers in a hidden layer neural network can (and should) be separated according to their functional characteristics.
- It’s a trial and error process. But for once, DON’T stick with your gut. Statistics all the way.
That’s it from us, folks. If you’re looking to do some more deep learning (there’s that pun again), check our blog and do pay attention to our courses on data science and machine learning. There is a lot of useful stuff. Stay tuned and learn data science!


