How to Train and Test Data Like a Pro

In data science, training data and testing data are two major roles. Evaluating the performance of a built model is just as significant as training and building the model because a model with unevaluated performance may produce false predictions and lead to serious complications. In order to prevent such situations and to ensure the accuracy of the predictions, you must test and validate the model well enough. This article discusses the process of training, validating, and testing data in machine learning.
Training and Testing data
To build and evaluate the performance of a machine learning model, we usually break our dataset into two distinct datasets. These two datasets are the training data and test data. Let’s have a closer look at each of these sub-datasets.
Training data
Training data are the sub-dataset which we use to train a model. These datasets contain data observations in a particular domain. Algorithms study the hidden patterns and insights which are hidden inside these observations and learn from them. The model will be trained over and over again using the data in the training set machine learning and continue to learn the features of this data. Later we can deploy the trained model and have accurate predictions over new data. These predictions will be based on the learnings from the training dataset.
Test data
In Machine learning Test data is the sub-dataset that we use to evaluate the performance of a model built using a training dataset. Although we extract Both train and test data from the same dataset, the test dataset should not contain any training dataset data. The purpose of creating a model is to predict unknown results. The test data is used to check the performance, accuracy, and precision of the model created using training data.
Difference between training data and test data
A comparison of training data vs test data can be listed below.
| Train data | Test data |
| Used to build a model | Used to evaluate the built model |
| Allocates a larger portion of data | Allocates a smaller portion of data |
| Further dividable for validation | Won’t be further divided |
But in some cases, we will be facing the issue of overfitting when working only with training and testing datasets. In overfitting, the trained model is performing well in making predictions with the training set, but it fails to generalize and make accurate predictions on the new data. By validating the model during the training process, we ensure that the model performs well even on new data. That is where we need a validation dataset.
What are validation data?
Validation data are a sub-dataset separated from the training data, and it’s used to validate the model during the training process. The information from the validation process assists us in changing parameters, classifiers of the model to get better results. So basically, validation data helps us to optimize the model.

How to split a dataset into training, validation, and testing sub-datasets
By now, you must have a clear understanding of what are training, validation, testing data, and why do we need them. Now let’s look at how we can split a data set into these three types of sub-datasets.
We need to consider about two things before we split a dataset. They are,
- The volume of the dataset
- Type of the model which you are going to train with the dataset.
The training set vs test set split ratio mainly depends on the above two factors, and it can be varied in different use cases. The split ratio will always be negotiated between the amount of data you have and the amount of data that is required to train and test the model.
Usually, the initial process of splitting the dataset is called the holdout method. In the holdout method, the dataset will be split into two parts which contain training data and testing data. Following are some of the most commonly used training data testing data split ratios.
- Train: 80%, Test: 20%
- Train: 67%, Test: 33%
- Train: 50%, Test: 50%
The split ratio is commonly represented as a percentage between 0 and 1. A ratio of train: 80% and test: 20% will be represented as 0.80 for training and 0.20 for testing. We will be using this representation later in this guide to define the testing set size and the test set size.
Once you have divided the dataset into training and testing sets using the holdout method, the training set will be again split to allocate a data portion for validation. Visual representation of the initial train split and the validation split can be depicted as follow.
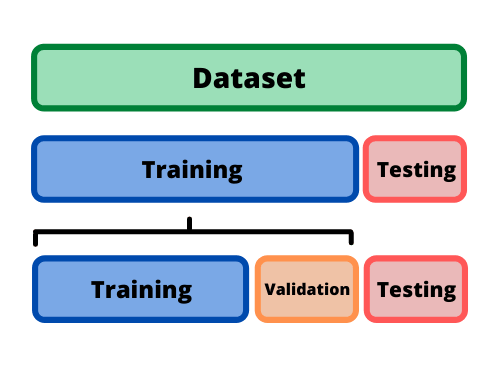
The validation split can be varied according to the cross-validation technique you will be using. There are various cross-validation techniques. Among them, let’s discuss K-Folds cross-validation and how the data is being divided when using K-Folds as an example.
In K-Folds cross-validation, the training dataset will be divided into K different sub-datasets.
K value refers to the number of folds or groups by which the training set is to be divided into. Choosing the K value should be done carefully. Once the K value is chosen, the value replaces the K. one of the most common tactics is K=10, which is called 10-Folds cross-validation. In 10-Folds cross-validation, the training set will be divided into equal ten folds. Then the validation accuracy will be calculated for each fold. The average validation accuracy of all folds will be considered as the final accuracy. Following visual representation will provide a more explanation about the 10-Folds cross-validation.
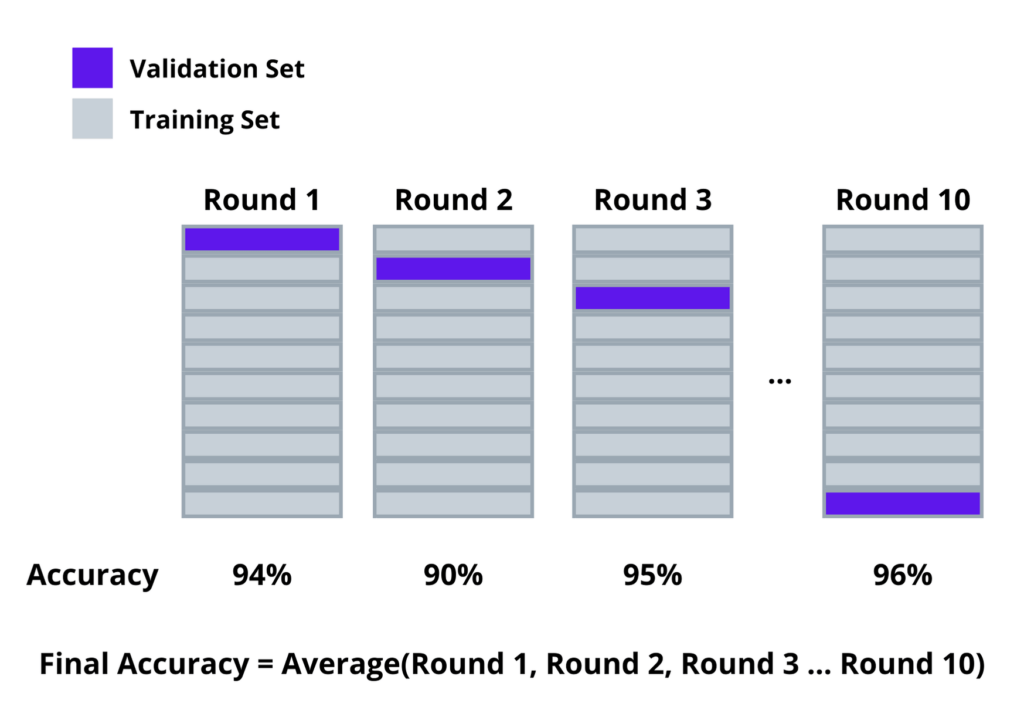
Likewise, we can split data for validation when using K-Folds cross-validation. Other validation techniques have various other ways of splitting data.
How to split a dataset using Scikit-learn
Now let’s look at how we can actually perform these splits for a dataset using a python library named Scikit-learn. We will be performing a basic train, test, and validation data split to a dataset using a model of Scikit-learn named train_test_split .
First of all, we need to import our data set into a pandas data frame, as shown below. I have named my data frame stroke_df. And we can also check the length of our data frame using the len() function shown below.
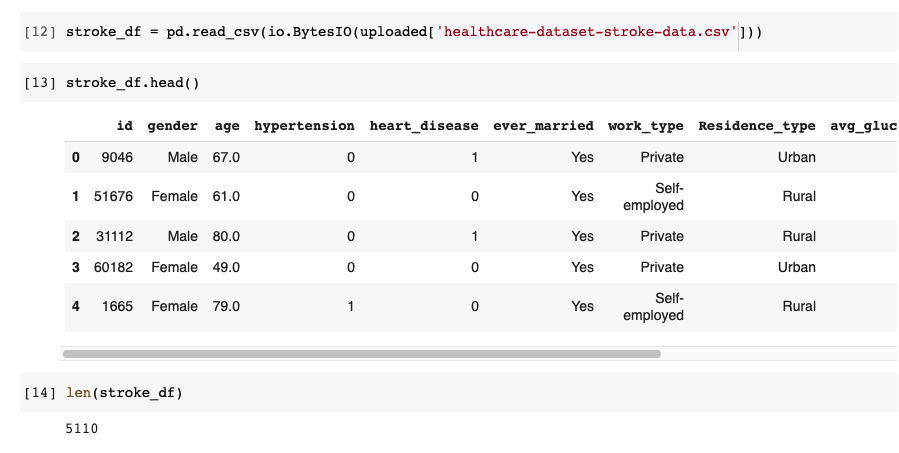
As you can see, there are 5110 rows in the stroke_df data frame. Now we can start splitting the data frame and check through the number of rows.
Let’s import the train_test_split model from Scikit-learn, as shown below.

Now let’s first split our data frame into a training set and test set. If you can recall, we have mentioned how to represent the testing set size. In this scenario, we will be splitting the stoke_df data frame in training: 80% & testing: 20% ratio. So we will be specifying the size of the test set as 0.2 using the test_size parameter.

Now, if you have a closer look at the above code snippet, you can see that the stroke_df data frame has been passed as the first parameter, and the size of the test set has been passed as the second parameter. And the stroke_df data frame has been divided into two data frames named train and test, and you can check the size of the data frame as shown above.
Once you have created your train and test data frames, you need to create the validation data frame next. For that, we will be splitting the training data frame again, as we discussed earlier. We will be defining the validation data set the size to be 15%(0.15) of the training set.
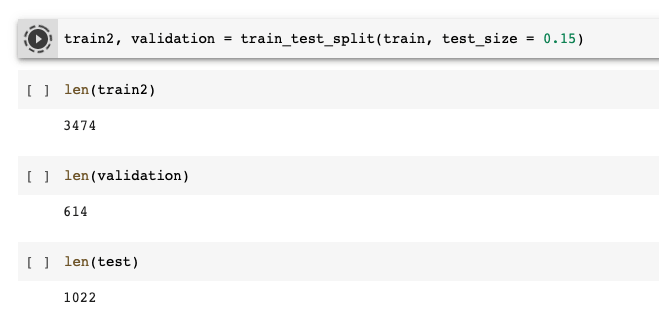
As you can see, this time, we have passed the train data frame as the first parameter, which means we are going to split the train set. We have also created two data frames named the train2 data frame, which contains 85% of data from the train data frame’s data, and the validation data frame now consists of 15% of the train data frame’s data. You can check the lengths of all train2, validation, and test data frames and notice that the test data frame hasn’t changed from the beginning.
Conclusion
In this tutorial, you have got a clear understanding of the training and testing datasets and why sometimes they aren’t sufficient. Then we have discussed the difference between training ad test data with training data vs test data comparison. We also looked into validation data in detail and the importance of it. We have then discussed how we can split and allocate data for training testing and validation purposes. Finally, we have split a dataset into training, testing, and validation sub-datasets using Scikit-learn train_test_split.
If you enjoyed the article, share it with your friends and subscribe to our email newsletter. Check out our blog, you will find a lot of interesting articles.



