How to Train a Neural Network Just Like a Guru

Technology advancements and innovations have taken on new dimensions in recent years. A significant case in point is artificial intelligence, a vast field of development in computer systems through subdivisions such as machine learning, deep learning, and of course, neural networks.
If you’re new to the world of artificial intelligence (AI), then you don’t want to miss out on learning how to train a neural network. This article seeks to make your learning process as simple as possible, and who knows? You will probably start training neural networks like a guru in no time. So, what are neural networks?
Neural networks are algorithms that identify patterns and are loosely modeled after the human brain. They use a kind of machine perception to perceive sensory data, marking or clustering raw data. This means that all real-world data, whether images, sound, text, or time series, are converted into the patterns understood by neural networks, numerical and stored in vectors. You can also take neural networks as computational models inspired by how the actual neural network in the human brain processes data.
If you have ever wondered how modern devices perform tasks such as your phone’s Face ID or how Siri, Cortana, and Alexa are activated by your merely saying ‘Hello,’ well, it’s all due to the help of neural networks. Neural networks currently offer the most effective solutions to a variety of image recognition, speech recognition, and natural language processing problems.
NEURAL NETWORK ARCHITECTURE
The human brain comprises about 1011 processing units called “neurons” that operate in parallel and exchange information via their connectors called “synapses.” These neurons sum up all information coming in and send a pulse through the axon to the next stage if the result is higher than the given potential called “action potential.” Similarly, an artificial neural network is made up of basic computing units called “artificial neurons,” each of which is linked to the others through weight connectors; these units then measure the weighted sum of the inputs and find the output using squashing or activation functions. Neural networks are classified into layers that you should be familiar with before knowing how to train a neural network.
- Input Nodes (Input layer): This layer does not perform any computations; instead, it simply passes information to the next layer (hidden layer most of the time). Layer refers to a group of nodes.
- Hidden Nodes (Hidden layer): Hidden layers are where intermediate processing or computation takes place; they perform computations and then move the weights (signals or information) from one layer to the next (another hidden layer or to the output layer).
- Output Nodes (Output layer): Finally, we use an activation function that maps to the desired output format in the Output Nodes (output layer).
So, how do neural networks learn? Well, they construct information from data sets in which the correct response is known ahead of time. The networks then improve their prediction accuracy by tuning themselves to find the correct answer independently.
The network accomplishes this by comparing initial outputs to a given correct response or goal. The initial outputs are modified using a cost function based on the degree to which they vary from the target values. Finally, the effects of the cost function are applied to both neurons and connections to change the biases and weights.
The great thing about neural networks is that once you know the basics of training a neural network, then you’re on your way to being a guru.
NEURAL NETWORKS TRAINING
It is important to note that neural networks training is a lot of work. To achieve a stellar degree of accuracy, these networks must be trained with a large amount of data and, as a result, computing power.
There are two ways to approach training: supervised and unsupervised training.
- Supervised training: This entails either manually “grading” the network’s efficiency or providing the desired outputs with the inputs to provide the network with the desired outputs. The network then compares its outputs to the desired outputs after processing the inputs. Errors are then propagated back through the device, causing the weights that power the network to be adjusted. As the weights are constantly tweaked, this mechanism repeats itself. The vast majority of networks use supervised instruction.
- Unsupervised training: This is when the network is left on its own devices to make sense of the inputs, but the output is not provided. Unsupervised instruction is used to characterize inputs in the first place. However, it is still just a shining promise that is not fully understood, does not fully function, and is therefore confined to the lab in the complete sense of genuine self-learning.
So now, how would you train a neural network? There are various methods of training associated with modern neural networks:
Optimization Algorithms Method
But most important of all and widely practiced is the use of a neural network training algorithm known as optimization algorithms or optimizers. Optimizers are algorithms for altering the characteristics of a neural network, such as weights and learning rate, to minimize losses. A neural network training algorithm includes but is not limited to the following;
- Gradient Descent: For finding the minimum of a function, gradient descent is a first-order iterative optimization algorithm. When using gradient descent to find a local minimum of a function, one takes steps proportional to the negative of the function’s gradient (or approximate gradient) at the current stage. As one takes action proportional to the positive of the gradient, one reaches the function’s local limit, and the process is known as gradient ascent. The formula is explained better below;
We can denote f(w(i)) = f(i) and ∇f(w(i)) = g(i). The method starts at a point w(0) and, until the upper limit is reached, moves from w(i) to w(i+1) in the training direction d(i)= −g(i). Therefore, the gradient descent method iterates in the following way:
w(i+1) = w(i) − g(i) η(i),
for i=0,1,…
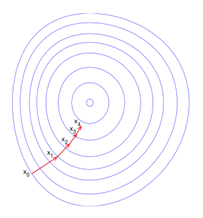
Gradient Descent
- Stochastic Gradient Descent: This is the traditional method for training neural networks (SGD). The problem with gradient descent is that it requires calculating the gradient from each sample factor to evaluate a new approximation of the weight vector, which can significantly slow down the algorithm. The idea behind speeding up the stochastic gradient descent algorithm is to calculate the new weight approximation using only one variable or a subsample. Stochastic training of neural networks is typical; that is, different pieces of data are used at various iterations. This is due to at least two factors.
- The data sets used for training are often too large to fit entirely in RAM and perform calculations quickly.
- Second, since the optimized function is typically non-convex, using different sections of the data at each iteration will aid in the model being stuck at a local minimum.
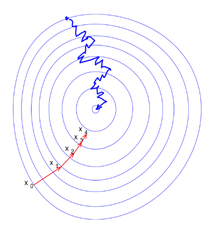
Stochastic Gradient Descent
Random Search Method
Random search methods are less efficient than standard search methods for simple objective functions. Still, they prove to be helpful in more complex cases where some of the objective function’s properties that enable rational search direction selection cannot be determined in advance. Such random search methods apply to any objective purpose, whether unimodal or multimodal. It is well known that a particular function (class of functions) can be constructed to not operate for every standard algorithm. Random search allows you to optimize any feature, though at varying levels of efficiency (sometimes very low).
Krylov Method
Krylov subspace methods are a series of successive matrix powers times the initial residual. The residual over the formed subspace is then minimized to form approximations to the solution. The conjugate gradient method assumes that the device matrix A is symmetric positive-definite, which is the most common method in this class. The minimal residual method is used to solve asymmetric (and probably indefinite) matrix A. Methods such as the generalized minimal residual method and the biconjugate gradient method have been developed for non-symmetric matrices.
NEURAL NETWORK TRAINING DATA
Now that you have a clue on some methods that will help you know how to train neural networks, you can now try your hand on a few neural network training data either sourced from the internet or something you have personally developed. Training data is made up of calculated samples and “solutions” that will aid the neural network in generalizing all of this data into a coherent input-output relationship.
Here are some neural network training examples to have an idea of what you can work on;
- Predictive Analysis: Neural networks can create associations between pixels in a picture and a person’s name using classification. This is referred to as a static forecast. It can make connections between current and future events when given enough of the correct data. It can go back and forth between the past and the future. In specific ways, the future event is similar to the mark. Neural networks can understand a string of numbers and predict the number most likely to occur next given a time series. Examples include;
- Predicting health stats (Heart rate, blood pressure)
- Predicting customer and employee turnover
- Grouping: The identification of similarities is known as clustering or grouping. Neural networks do not need labels to detect similarities. This includes;
- Search for related things by comparing records, pictures, or sounds.
- Anomaly detection: Detecting deviations, or abnormal activity, is the inverse of detecting similarities. Unusual activity is often associated with items you want to track and avoid, such as fraud.
- Classification: All classification tasks include labeled datasets; for a neural network to learn the association between labels and data, humans must pass their information to the dataset. This includes;
- Face detection, image identification, and facial expression recognition.
- Recognize emotion in voices, detect voices, recognize speakers, transcribe speech to text.
- Recognize sentiment in text and classify it as spam or fraudulent.
A neural network can be trained using any labels that humans can create and any outcomes you care about and that correspond to data.
You can also check out any neural network tutorial on YouTube or check out our channel here.
CONCLUSION
There are, of course, some questions that you might have, which are both expected and understandable. One might be you asking a question like “how much does it cost to train a neural network?” or maybe “how can I improve my neural network performance?”. Well, no need to look far because your answers are right here.
- If you ask how much time, you should know it takes between 2-4 hours of coding and about 1-2 hours of training, if you are versed in programming and if the project is not a very complex one. If not, it can take 3-5 days for programming and training. If you mean cost in terms of money, you will need to consider the project you are taking on. A simple yet efficient project such as a computer vision model can cost roughly $300. But for large-scale models which use high processing units, you might spend between $7,000 and $25,000.
- To combat problems associated with neural networks; such as its failure to converge due to its low dimensionality, there are a few ideas to help you to improve the neural network performance, and they are;
- Increase hidden layers.
- Change the activation function.
- Increase the number of neurons.
- Increase data input.
- Change learning algorithm parameters.
Neural network training is one that you will thoroughly enjoy if you are trying to diversify your artificial intelligence portfolio. It doesn’t hurt that it is such a high-in-demand skill in the job market these days, an average salary of about $76,969. You can be sure that learning about Neural networks is the right choice. To stay up to date on all news regarding neural networks, artificial intelligence, and so much more, then subscribe to our newsletter today and, of course, share with your socials to get the word out!



