TensorFlow 2.0: The Complete Beginner’s Guide

Wouldn’t you love to have a brain like Google?
Not the search engine itself – we’re talking about the Google Brain team, an elite group of programmers, developers and scientists that are constantly developing cool new stuff.
Like TensorFlow 2.0, for instance.
Yes, Google definitely get to work on all cutting-edge technology, especially when it comes to AI and machine learning. AI is a big focus for the Google Brain at the moment, which led to the release of TensorFlow in 2015.
We’ve decided to pick Google’s Brain and create a comprehensive beginner’s guide to TensorFlow.
This Tensorflow guide dives deep into:
- What TensorFlow is and how it works
- The benefits of using TensorFlow
- How TensorFlow 2.0 has improved on the original platform
- How TensorFlow 2.0 compares to PyTorch 1.3
What is TensorFlow
TensorFlow is a platform that can be used to build AI and machine learning models. Machine learning is a complex and mathematically demanding area of data science. However, the release of TensorFlow has made it much easier to create and implement machine learning models.
In a nutshell, TensorFlow makes it easier to gather data, train models, serve predictions, and refine future results. It’s an open source library for quantitative computation and deep-learning or machine learning on a large scale.
TensorFlow combines a number of machine learning algorithms, models and neural networks, and links them by use of a common framework. It uses Python for a nice, user-friendly frontend and C++ for the high-performance computations.
Great – that’s all well and good, but
What Is Tensorflow Used for In Practice?
Good question.
Initially, neural networks created in TensorFlow were applied to solve simple problems that involved classifying data, such as handwritten digit classification or automatic vehicle registration plate recognition with digital cameras. These days, with the availability of high computational Graphics Processing Units (GPUs), far larger amounts of data can be used to train the neural networks, with quantities reaching into terabytes. The improved computational power enables more complicated applications such as “image semantic segmentation”.
The list of TensorFlow applications is vast. Here are just a few of them:
- Image recognition
- Handwritten digit classification
- Word embedding
- Natural Language Processing (NLP)
- Recurrent Neural Networks (RNN)
- Sequence-to-sequence models
- Object detection
- Image semantic segmentation
- Partial Differential Equation (PDE) – based simulations
The big breakthrough to simplifying the creation of machine learning models was the way in which TensorFlow allows users to create dataflow graphs. Like a flowchart, dataflow graphs show how data moves through a machine learning training model, governed by a series of processing nodes.
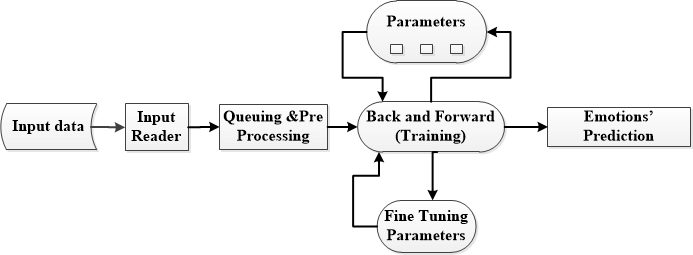
IMAGE SOURCE: https://www.researchgate.net/figure/TensorFlow-dataflow-graph-for-training-tweets-data_fig2_335573307
The dataflow graph above is based on a machine learning model that is designed to measure people’s reaction or mood to certain products, news items, etc. by distinguishing emotions from a large corpus of text, in this case hundreds of thousands of tweets.
Each processing node is a logical or mathematical operator, and the connections between nodes is known as a multidimensional data array, or tensor – hence TensorFlow.
The dataflow graphs nodes, tensors and applications are programmable in Python, making it easy for the developer to set up the dataflow and run data between the nodes. The actual mathematical operations or algorithms are written as C++ binaries, to allow high-performance computations.
The Benefits of TensorFlow
The number one benefit of TensorFlow is “abstraction”. In other words, TensorFlow removes some of the complexity of machine learning modeling, by removing the need to actually implement algorithms and link up function outputs and inputs. All that is done behind the scenes with TensorFlow. This means that the developer or AI engineer can concentrate on coding the logical flow of the application. This greatly speeds up the process of building and implementing the models.
Another major benefit of TensorFlow is that it has been created by Google, which means there is significant development funding, fuelling other applications to be released as add-ons and also regular updates. That’s why there is already a 2.0 version that significantly improves on the first, after just two years.
What’s New in TensorFlow 2.0?
There are a number of new features and improvements in TensorFlow 2.0. Let’s go through them one-by-one.
1. Eager Execution
TensorFlow 2.0 allows for much more user-friendly and convenient analysis and evaluation of dataflow graphs. There’s an “eager execution mode” that allows users to analyze and modify each graph operation node individually, as opposed to modeling the entire dataflow graph as one object and analyzing it as one. This allows for editing the code line-by-line in Google Colab or Jupyter notebook.
For instance, take the simple example of adding two variables. In the original TensorFlow, this was a laborious task, as you couldn’t simply use the intuitive Python code add.(x,y) to add them together after creating the variables. This is because TensorFlow needs to execute the graph before assigning values to the variables, as in the code below where x=5 and y=3:

When evaluating and debugging models, this causes a big problem as it slows the process down considerably.
In TensorFlow 2.0, eager execution solves this problem. The whole process is made much quicker and easier, as the graph no longer needs executing to define the variables. This is the same simple variable addition, this time in TensorFlow 2.0:

2. Default Keras API
Keras is an open-source neural-network library that is simple to use. The syntax of Keras is very much like Python as it is intuitive and uncomplicated. The inclusion of Keras as a default API means it is now easier than ever to build an artificial neural network model in TensorFlow 2.0.
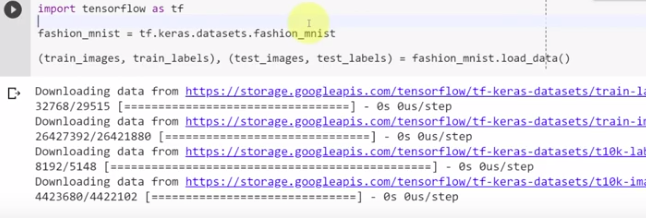
For example, if you want to build a “mini-brain” to classify fashion objects – sneakers, sweaters, pants, dresses, etc. you can do this in just a few lines of code. Keras allows you to very easily import readily available datasets, training images, training labels, testing images and testing labels.
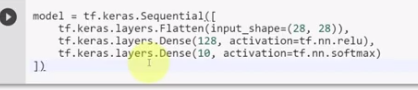
The next step is to build a simple artificial neural network model. Believe it or not, this can be done in just one line of code! After defining the model as sequential, we then define the input as images that are 28 by 28 pixels. We then define a “Dense” (fully connected) layer, which consists of 128 neurons with a “relu” activation function (rectified linear units). Finally we define the output, which is another “Dense” layer, with 10 class outputs (fashion items) and a “softmax” function which gives us a probability distribution output for each class.
Then we compile the model using an optimizer (in this case “adam”) and we specify the loss as “sparse_categorical_crossentropy”, as we are categorizing the data into classes, which is non-binary. We also set the metrics, in this case we just want to improve the accuracy of the predictions coming out of the model.

Now that we have defined and compiled our model, we are ready to fit it in preparation for training. We set the training images and labels and specify the amount of epochs to train the model over, in this case we set it to 5.

The model is then executed and training takes place. After some time we get our results:
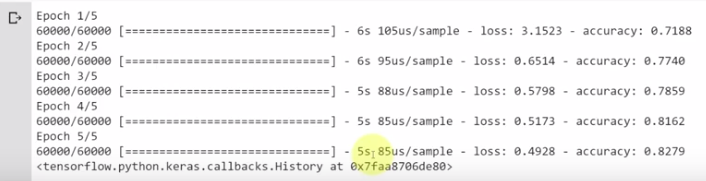
As you can see, the accuracy has improved from 71.88% in the first epoch, to 82.79% by the end of the fifth epoch.
This example just goes to show how easy it is to create a “mini-brain” or artificial neural network using TensorFlow 2.0 now that Keras is used as the default API.
3. TensorBoard
TensorBoard is now fully integrated with TensorFlow 2.0 and can be called up easily within the platform. TensorBoard allows you to track the progress of networks and visualize metrics as they change over time. Graphs can be automatically produced that show the progress of accuracy or loss, against time. It also has a performance dashboard that helps users to optimize device placement and minimize bottleneck during model execution and training.
Using the same example as the previous section, we have added a line of code before executing the model that calls up TensorBoard.
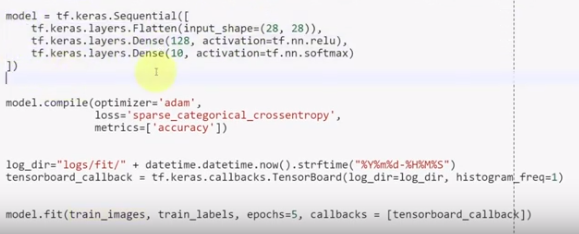
When the training is complete, use the following command to launch TensorBoard:
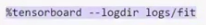
This brings up the performance dashboard, which displays a range of customizable visualizations.
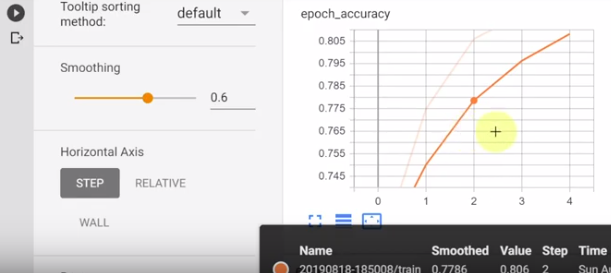
You can also use TensorBoard to view the dataflow graph:
4. Distributed Strategy
Distributed strategy allows you to build your model once, then decide how you want to use it over multiple GPUs or even TPUs (Tensor Processing Unit).
To run a distributed strategy is very straightforward in TensorFlow 2.0. You simply add a couple of lines of code to set out the strategy. For example:
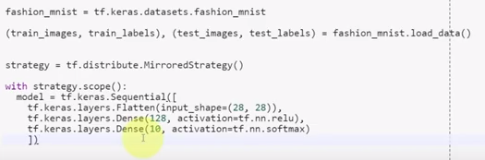
Also, in Google Colab, you can adjust the runtime settings to use cloud GPUs and TPUs. TPUs are around ten times faster than a normal CPU, so allow for much more efficient training of artificial neural networks. Being able to apply Google’s cloud tools so easily is an exciting development for deep learning modeling and data science, and will speed up progress in AI as a whole.
To learn more about creating neural networks in TensorFlow 2.0, check out our comprehensive course that gives you all the practical experience you’ll need.
TensorFlow 2.0 vs. PyTorch 1.3
Similar to TensorFlow, PyTorch is an open source library for machine learning, but is based on the Torch library. It was developed by Facebook’s AI Research (FAIR) lab, and originally released in 2016. PyTorch 1.3 was released towards the end of 2019 and has proven to be a close contender to TensorFlow 2.0.
The final section of this Tensorflow beginner tutorial will focus on the comparison between Google’s TensorFlow 2.0 and Facebook’s PyTorch 1.3.
1. Dynamic vs. Static Graphs
The TensorFlow 2.0 framework relies on two main components:
- A large library of definitions for computational graphs and runtime to execute them.
- Computational or dataflow graphs.
The computational graphs are generated statically within TensorFlow 2.0 before the code is executed. The computational graphs allow for parallelism which speeds up training of the model.
The PyTorch 1.3 framework also relies on two main components:
- Dynamic creation of computational graphs.
- Autograds which differentiates the dynamic graphs.
This means that in PyTorch 1.3, the graphs change and nodes are executed as the model runs. This is more in keeping with the Python way of working, and as such PyTorch 1.3 feels more tightly integrated with Python.
It’s worth noting that TensorFlow 2.0 can handle dynamic graphs, but a separate library such as TensorFlow Fold needs to be implemented to make it possible, whereas PyTorch has the capability built-in.
2. Training and Output Visualization
TensorFlow 2.0 is the clear winner when it comes to visualizing the training process and outputs.
TensorBoard is the visualization library for TensorFlow and has a wide range of features and tools, including:
- Metric tracking and visualization, e.g. loss and accuracy
- Computational graph visualizations, e.g. operations and layers
- Histogram views of tensors as they vary over time, e.g. weights and biases.
- Display of images, audio and text data
- Profiling TensorFlow programs.
Visdom is the visualization library for PyTorch 1.3, but by comparison has limited features, which include:
- Callback processing and handling
- Plotting basic computational graphs
- Managing training environments.
3. Deployment
To deploy trained models for production, TensorFlow uses a framework called TensorFlow serving which uses REST Client API. This means that the completed models can be deployed directly.
However, PyTorch doesn’t provide a deployment framework, so a backend server such as Django or Flask must be used.
4. Overall Comparison
Pros:
| TensorFlow 2.0 | PyTorch 1.3 |
|---|---|
| Built-in simple, Keras API | Python-esque coding |
| Good visualizations with TensorBoard | Dynamic computational graphs |
| Production-ready with Tensor Serving | Quick editing |
| Open source | Open source |
| Good support | Good support |
Cons:
| TensorFlow 2.0 | PyTorch 1.3 |
|---|---|
| Static computational graphs | Third party app needed for visualizations |
| More difficult to make quick edits | Need to use API server for production |
We hope you enjoyed this guide to TensorFlow 2.0 and that it has inspired you to learn more about building artificial neural networks. If so, head on over to Udemy and check out our Tensorflow 2 tutorial – TensorFlow 2.0 Practical course.
